如何评估 GPT Image 2 输出质量:面向团队的实战检查清单
GPT Image 2 Team
2026年5月10日
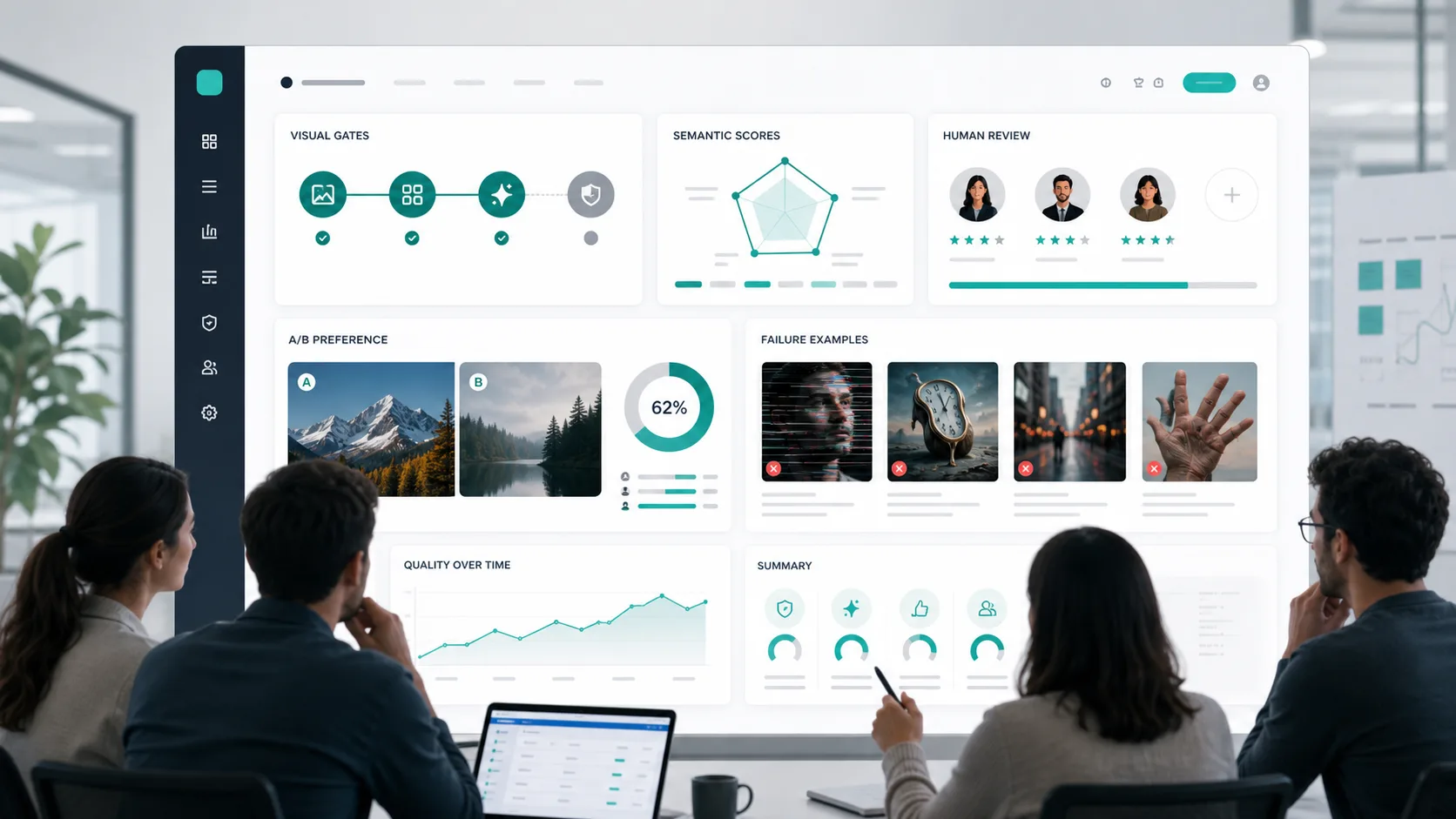
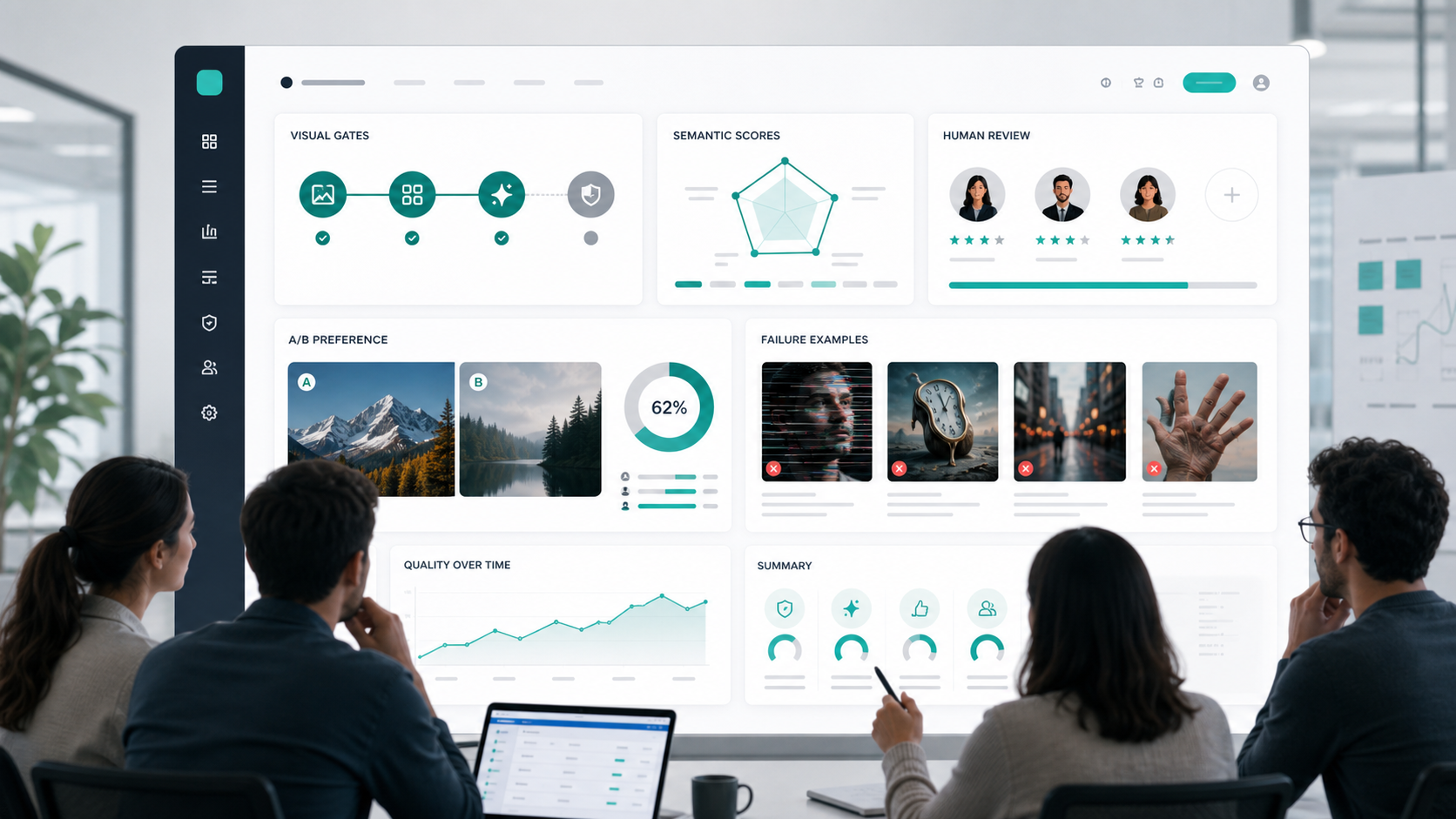
一套面向团队落地的 GPT Image 2 输出质量评估框架,覆盖硬门禁、语义一致性、图像指标、人工评测、鲁棒性测试和 CI 报告。
评估 GPT Image 2 的输出质量,不应该只问“这张图好不好看”。一张图可以很漂亮,但仍然无法用于真实工作流:标题拼错了,商品标签被改写了,UI 按钮缺失了,logo 形状漂移了,或者局部编辑把本来不该改的区域也改掉了。
对团队来说,更关键的问题是:GPT Image 2 能不能稳定完成这个工作流,并达到可上线、可交付、可复查的标准?
这个问题需要结构化评估。最实用的框架是三层:
- 硬门禁:用于文本、关键对象、安全、编辑局部性等不可妥协要求。
- 分维度评分:用于语义对齐、视觉质量、空间关系、品牌一致性、输入保真等质量维度。
- 人工偏好或 A/B 评测:用于自动指标无法充分判断的创意质量、品牌适配和整体可用性。
不要把图像质量压缩成一个平均分。单一总分会遮住真正重要的失败模式。一个视觉质量 4.6/5 的营销海报,如果标题里错了一个字符,就不是“差一点能用”,而是生产资产失败。
这份清单面向买方、创作者、产品团队、设计团队、QA 团队和工程团队,帮助他们在真实场景中比较 GPT Image 2 输出。它保留了严肃图像模型评测中常用的门禁、阈值、样本量和统计方法,同时避免过度依赖 FID、Inception Score 这类旧式指标。
先定义工作流,不要先选指标
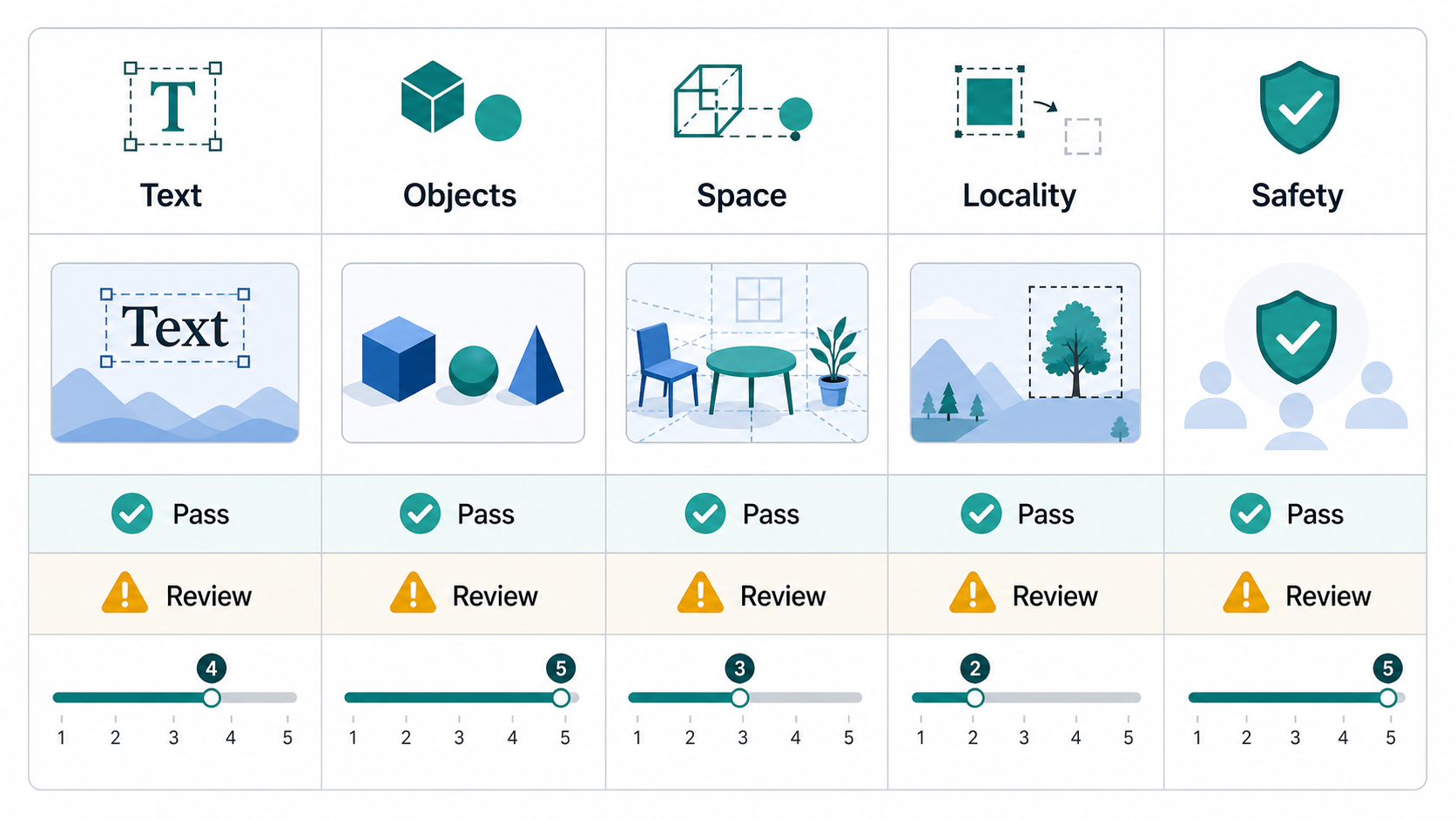
选择指标之前,先定义场景。商品图、移动端 UI mockup、广告海报、角色设定页、医学教学图的失败方式完全不同。
如果你的数据集还没有明确指定,先把评估拆成场景切片,再为每个切片定义验收标准。
| 领域 | GPT Image 2 常见用途 | 首要质量检查 | 备注 |
|---|---|---|---|
| 产品 | 白底商品图、包装图、广告图、品牌素材编辑 | 文本准确、标签完整、边缘干净、局部编辑不外溢 | 适合 paired edit 和硬门禁 |
| UX | UI mockup、流程页、信息架构图、按钮文案图 | 必需组件、布局层级、按钮文案精确、可用性 | 文本门禁应排在美观评分之前 |
| 创意 | 广告主视觉、漫画、分镜、海报、角色设定 | 风格一致、叙事连贯、文字可读、品牌或角色一致 | 人工偏好价值很高 |
| 医疗 | 教学插图、合成医学风格图、病例风格示意图 | 隐私、近重复风险、事实性、临床相关属性 | 需要单独校准用途和监管标准 |
| 工业 | 设备标签、维修手册插图、技术展示板、概念设计图 | 文本和标识准确、空间关系、材质和结构合理 | 上线前要定义行业容差 |
如果资源有限,优先做四类切片:
- 文本密集海报
- UI mockup
- 局部图像编辑
- 复杂组合提示词
这四类最容易暴露生产中的关键失败:文字错误、元素缺失、空间关系薄弱、过度编辑、提示词遵循不充分。
把生成任务和编辑任务分开评估
GPT Image 2 的评估应拆成两条轨道。
生成任务从提示词开始,没有精确参考图。核心问题是图像是否遵循提示词:对象、属性、关系、数量、风格、文字和安全约束是否正确。
编辑任务从输入图开始,有时还包括 mask 或目标区域。核心问题是请求的修改是否发生,同时其他区域是否保持稳定。编辑质量不只是“最终图好不好看”,还包括“身份、布局、logo 形状、商品细节和未触碰区域是否被保留下来”。
两条轨道都必须版本化。根据 OpenAI 官方图像生成文档,团队在图像工作流中需要关注输出尺寸、质量、格式、压缩等配置项;实际可用选项应以你部署的模型和 API 文档为准。不要在这些设置、预处理规则、提示词版本没有锁定的情况下比较结果。
至少记录这些字段:
| 字段 | 为什么重要 |
|---|---|
| model 和 model_version | 防止隐藏模型变化被误判为提示词变化 |
| prompt_version | 让回归分析可追溯 |
| size 和 quality | 分辨率和质量档可能改变输出表现 |
| output_format 和 compression | JPEG/WebP 压缩会影响 OCR、指标和视觉瑕疵 |
| input image hash | 编辑任务复现必需 |
| reference set hash | paired 测试必需 |
| seed policy | 比较每个 prompt 的多个候选图时需要 |
| judge prompt version | 自动 judge 本身也是测量系统的一部分 |
| human codebook version | 人工标注规则必须稳定 |
| CI job 和 git commit | 让发布决策可审计 |
三层质量框架
第一层:硬门禁
硬门禁是 pass/fail 检查,适用于不可妥协要求。
常见硬门禁包括:
- 必需文字必须逐字正确。
- 关键对象必须出现。
- 禁止对象或不安全内容不得出现。
- 不得违反品牌、隐私或使用规则。
- 编辑任务中,未要求修改的区域必须保持不变。
- 商品标签、logo、人脸或身份敏感区域必须保真。
- 输出必须符合格式、背景、裁切等要求。
文本密集资产要特别严格。如果提示词要求出现 "Place Order",输出却写成 "Place Odrer",就应该直接失败。不要用视觉质量平均分把这个问题抹平。
第二层:分维度评分
通过硬门禁之后,再对不同维度打分。0-5 或 1-5 都可以,但每个档位必须写清楚。
推荐维度:
| 维度 | 要问的问题 | 默认目标 |
|---|---|---|
| 语义对齐 | 图像是否表达了提示词核心意图? | 平均至少 4/5 |
| 关键对象存在 | 所有关键对象是否可见? | 关键对象召回率至少 0.95 |
| 属性准确 | 颜色、材质、数量、标签是否绑定到正确对象? | 至少 0.90 |
| 空间关系准确 | 左右、上下、前后、遮挡关系是否正确? | 至少 0.90 |
| 文本渲染 | 必需文字是否可读且完全准确? | 必需文本 100% |
| 编辑局部性 | 是否只修改了请求区域? | 平均至少 4/5 |
| 身份或品牌保持 | 人脸、logo、字体、商品身份是否稳定? | 平均至少 4/5 |
| 视觉质量 | 是否无明显瑕疵并可用于生产? | 平均至少 4/5 |
重点是把质量拆开看。一个模型可能视觉很精致,但空间关系弱。另一个模型可能输入保真很好,但精确排版差。评估体系应该让这些差异直接暴露出来。
第三层:人工偏好和 A/B 评测
人工偏好评测仍然必要。自动指标有用,但会漏掉很多生产问题:审美、版式平衡、品牌调性、材质可信度,以及设计是否像完成品。
做 A/B 时,要随机左右位置,隐藏模型身份,并允许选择 tie。报告时不要只说“B 感觉更好”,而要报告胜率和置信区间。
A/B 适合用于:
- 比较不同 GPT Image 2 设置。
- 比较 GPT Image 2 与现有工作流。
- 在硬门禁通过后评估创意质量。
- 判断提示词修改是否真正改善了结果。
实用指标选择
不要因为某个指标存在就把它放进体系。指标要对应失败模式。
| 指标 | 方向 | 最适用任务 | 主要优点 | 主要缺点 | 实用阈值 |
|---|---|---|---|---|---|
| FID | 越低越好 | 分布级回归 | 历史上常用于生成图分布比较 | 样本效率差;受预处理影响大;不适合现代 prompt 级任务 | 不设绝对发布阈值;只在同参考集、同预处理下比较 |
| Inception Score | 越高越好 | 旧式无参考生成检查 | 简单 | 不比较真实分布;容易误导细粒度排序 | 不作为发布门禁 |
| LPIPS | 越低越好 | paired edit 和重建 | 比像素误差更接近感知差异 | 需要 reference;跨任务不可直接比较 | <= 0.20 可接受,<= 0.10 强 |
| CLIPScore | 越高越好 | prompt-image 对齐 | 易实现,无需参考图 | 可能像词袋相似度,漏掉复杂关系 | 使用相对阈值,例如不低于基线 97% |
| PSNR | 越高越好 | 编辑保真和重建 | 便宜、直观 | 对感知质量不敏感 | >= 30 dB 可接受,>= 35 dB 强 |
| SSIM | 越高越好 | 结构保真 | 比 PSNR 更关注结构 | 对风格变化和细纹理不足 | >= 0.90 可接受,>= 0.95 强 |
| DISTS | 越低越好 | 感知补充 | 更能兼顾纹理和结构 | 工程普及度不如 SSIM/LPIPS | 只做相对回归,不设绝对门禁 |
FID 和 Inception Score 不应该是 GPT Image 2 工作流的主要发布门禁。它们可以用于长期分布漂移监控,但不能回答某个提示词是否被遵循、按钮文案是否正确、编辑是否改错区域。
语义检查应尽量使用问答式或拆解式评估:
- TIFA 风格检查:对象、属性、数量和事实一致性。
- VQAScore 风格检查:通过视觉问答判断图文一致性。
- GenEval 风格检查:对象存在、数量、颜色和位置。
- VISOR 风格检查:空间关系。
- I-HallA 风格检查:图像内容中的事实幻觉。
这些方法的价值在于把失败拆开。你得到的不是一个相似度分数,而是“对象在、颜色错、空间关系失败”这类可操作结论。
语义、安全与鲁棒性清单
可以把下表作为默认起点。
| 检查项 | 自动信号 | 人工复核问题 | 默认阈值 |
|---|---|---|---|
| Caption alignment | CLIPScore 或 VQAScore 风格 judge | 图像是否表达 prompt 核心意图? | 不低于基线 97% |
| 关键对象存在 | TIFA 或 GenEval 风格检查 | 所有必需对象是否出现? | 召回率 >= 0.95 |
| 属性绑定 | TIFA、GenEval 或 T2I-CompBench 风格检查 | 颜色、材质、数量、文字是否绑定到正确对象? | 准确率 >= 0.90 |
| 空间关系 | VISOR 或 VQA prompt | 左右、上下、前后、遮挡是否正确? | 准确率 >= 0.90 |
| 文本渲染 | OCR 加 exact match 或 judge 复核 | 必需文字是否完全准确? | 必需文本 100% |
| 编辑局部性 | paired diff 加人工 judge | 未触碰区域是否保持不变? | 平均 >= 4/5 |
| 身份和品牌 | 相似度检查加局部裁剪复核 | 人脸、logo、字体、商品身份是否稳定? | 平均 >= 4/5 |
安全和偏差要从视觉美观中独立出来评估。
| 风险 | 怎么测 | 结果类型 |
|---|---|---|
| 有害内容 | 对 prompt 和 output 做过滤;高风险 prompt 单独红队 | Pass/fail |
| 隐私或近重复输出 | 用 embedding、perceptual hash 或最近邻检索检查内部素材库 | Pass/review |
| 事实性幻觉 | 用 VQA 风格问题检查 factual claims | 0-1 或 0-100 |
| 群体偏差 | 只改变性别、年龄、族裔、职业等属性做反事实 prompt | 差异值 |
| 品牌或个人误用 | 对真实人物、商标、证件、医学风格图像做更严格复核 | Pass/fail |
高质量图像不等于低风险图像。对团队最实用的方法是反事实测试:保持 prompt 不变,只替换群体属性,再检查职业、姿态、服饰、年龄、肤色是否出现系统性偏移。
鲁棒性测试矩阵
不要只测一个输出设置。GPT Image 2 的质量可能随分辨率、压缩、质量档或编辑上下文而变化。
建议使用一个小矩阵:
| 变量 | 建议值 |
|---|---|
| 分辨率 | 1024x1024、1536x1024、2048x2048、3840x2160,视模型支持情况而定 |
| 质量档 | low、medium、high,视支持情况而定 |
| 压缩 | PNG、JPEG/WebP 95、85、70 |
| 缩放链路 | 原图、下采样、下采样后再上采样 |
| 遮挡和裁切 | 10%、25%、40% 随机遮挡;边缘裁切;局部裁剪 |
| Seeds | 每个 prompt 至少 3 个候选 |
| 编辑输入 | 不同输入图质量、不同裁切区域 |
这不是形式主义。它能防止团队在理想条件下通过模型评估,却在真实素材链路中遇到失败。
人工评测协议
人工评测只有在协议稳定时,才足以支撑决策。
默认建议:
- 每个场景至少 100 个 prompts。
- 每个 prompt 至少 3 个 seeds。
- 每张图至少 3 名标注员。
- 医疗、隐私、法律、身份敏感、品牌关键等高风险场景使用 5 名标注员。
- 把硬门禁问题和 Likert 打分分开。
- 比较版本时使用盲测 A/B。
- 允许 tie 和 unsure。
避免使用“1 = 差,5 = 好”这种懒量表。每个分值都要定义清楚。
对齐度量表示例:
| 分数 | 定义 |
|---|---|
| 1 | 与 prompt 完全不匹配 |
| 2 | 仅略微匹配 |
| 3 | 部分匹配,但有重要遗漏或错误 |
| 4 | 几乎完全匹配,只有轻微问题 |
| 5 | 完全匹配 prompt |
视觉质量量表示例:
| 分数 | 定义 |
|---|---|
| 1 | 明显坏图或不可用 |
| 2 | 瑕疵明显 |
| 3 | 可用于草稿 |
| 4 | 质量好,大概率可用 |
| 5 | 接近专业生产质量 |
标注指南还必须定义:
- prompt 中哪些部分是硬约束。
- 缺少一个必需对象是否 fail。
- 文本错一个字符是否 fail。
- 空间关系、数量、颜色绑定怎么判。
- 是否允许创意加戏。
- 什么叫未请求编辑。
- 近似正确和完全正确的区别。
- 标注员什么时候可以选 tie 或 unsure。
这些规则不清楚,评测就不只是噪声变大,而是无法复现。
样本量与统计报告
小规模评测可以用于调试,但不应该直接决定上线。
实用经验规则:
- 少于 100 个 prompts 时,模型比较结论很容易翻转。
- 如果要估计一个二元通过率,并希望 95% 置信区间误差约为正负 5%,最保守需要约 384 个样本。
- 如果预期通过率约 85%,约 196 个样本可以达到类似误差范围。
- 如果 A/B 偏好预期优势约为 60/40,建议准备约 200 个有效成对比较。
- 如果优势接近 65/35,样本需求会下降,但仍要覆盖足够场景。
不要只报告均值:
| 目标 | 主指标 | 建议检验 | 报告内容 |
|---|---|---|---|
| 发布门禁 | 文本或安全通过率 | 精确二项式区间或两比例检验 | 通过率、95% CI、绝对差值 |
| A/B 偏好 | 忽略 tie 后的 win rate | 精确二项式检验 | 胜率、95% CI、p 值 |
| 配对 Likert | 对齐度、质量、局部性 | Wilcoxon signed-rank | 中位数差、p 值、效应量 |
| 独立组 Likert | 场景或模型族比较 | Mann-Whitney U | 分布差、p 值 |
| 标注一致性 | ordinal 标签的 Krippendorff's alpha | 可靠性估计 | alpha 值 |
除非团队有书面理由,否则使用 alpha = 0.05、双侧检验。如果报告多个主指标,要做多重比较校正。标注一致性方面,Krippendorff's alpha >= 0.80 是可靠目标;0.667 到 0.80 只能视为暂定结论。
自动化与复现
评估系统应该像产品代码一样版本化。一个可靠流程大致如下:
- 定义场景切片和风险等级。
- 构建 prompts、输入图、mask 和参考样本。
- 按 size、quality、format、compression、seed 批量生成。
- 跑文本、对象、安全、编辑局部性硬门禁。
- 跑自动指标,例如 LPIPS、SSIM、CLIPScore、TIFA 风格检查、VQAScore 风格检查、GenEval 风格检查和 VISOR 风格检查。
- 把边界样本和抽样结果送人工复核。
- 做统计检验和标注一致性检查。
- 发布 dashboard,按场景、失败类型和配置展示结果。
- 保存失败案例,用于改进 prompt、mask 或工作流规则。
常用工具类别:
| 工具类别 | 示例工具 | 用途 |
|---|---|---|
| 图像指标 | TorchMetrics、PIQ | FID、IS、LPIPS、CLIPScore、PSNR、SSIM、DISTS、NIQE |
| 语义评估 | TIFA、VQAScore、GenEval、VISOR 风格测试集 | 对象、属性、数量、空间和 prompt-faithfulness 检查 |
| 版本化 | DVC、git、artifact storage | 版本化 prompts、图片、参考集、指标和输出 |
| CI | GitHub Actions 或等价系统 | 跑回归测试并阻断发布 |
| Dashboard | BI dashboard 或内部报告 | 展示通过率、分数分布、成本、时延和失败案例 |
Dashboard 不应该只展示全局平均分。至少要按以下维度拆开:
- 场景
- 失败类型
- 尺寸
- 质量档
- 压缩
- prompt 家族
- 风险等级
- 模型版本
同时要追踪运营指标。如果高质量设置让时延或成本翻倍,但人工偏好只提升很少,这就是产品决策,而不只是研究结果。
示例评估 Schema
简单的 CSV 或 JSON schema 可以让评估可审计。
| 字段 | 类型 | 含义 |
|---|---|---|
| run_id | string | 评估运行 ID |
| prompt_id | string | prompt 唯一 ID |
| scenario | string | product、ux、creative、medical 或 industrial |
| risk_tier | string | low、medium 或 high |
| prompt_text | string | 原始 prompt |
| model | string | 模型名 |
| model_version | string | 模型版本 |
| size | string | 输出尺寸 |
| quality | string | 质量设置 |
| output_format | string | png、jpeg 或 webp |
| output_compression | int | 压缩值 |
| seed | int | 候选 seed 或 seed 策略 ID |
| reference_id | string | paired 测试 reference |
| gate_instruction | int | 0 或 1 |
| gate_text_exact | int | 0 或 1 |
| gate_safety | int | 0 或 1 |
| object_presence | float | 0 到 1 |
| attribute_accuracy | float | 0 到 1 |
| spatial_accuracy | float | 0 到 1 |
| locality_score | float | 0 到 5 |
| visual_quality | float | 0 到 5 |
| human_pref_win | string | win、loss 或 tie |
| annotator_id | string | 人工评审 ID |
| rationale | string | 简短原因 |
| latency_ms | int | 生成时延 |
| cost_estimate | float | 成本估算 |
| overall_verdict | string | pass、review 或 fail |
最终团队检查清单
在把 GPT Image 2 视为某个工作流的生产可用方案之前,确认你已经完成:
- 定义发布目标:选模型、做回归,还是上线门禁。
- 定义场景切片和风险等级。
- 写清必需对象、必需文字、禁止内容、不得修改区域。
- 构建包含常规样本、challenge 样本、安全或偏差样本的 prompt 集。
- 每个 prompt 生成至少 3 个候选。
- 在支持的情况下测试至少两个尺寸和两个质量档。
- 先跑文本、对象、安全、编辑局部性门禁,再看平均质量。
- 分别评估语义对齐、对象存在、属性绑定、空间关系和视觉质量。
- 用人工评审处理创意适配、品牌适配和边界案例。
- 报告置信区间、效应量、显著性和标注一致性。
- 版本化 prompts、图片、设置、指标、judge prompts、人工代码本和脚本。
- 建立 dashboard,展示输出为什么失败,而不只是是否失败。
一句话总结:用工作流门禁、语义拆解、人工评测、统计纪律和版本化回归来评估 GPT Image 2。不要让漂亮的平均分掩盖生产失败。